Weakly Supervised One-stage Vision and Language Disease Detection using Large Scale Pneumonia and Pneumothorax Studies
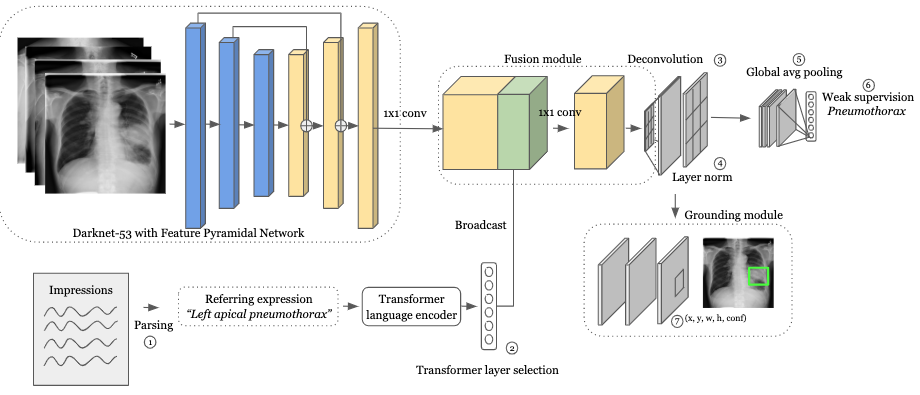
Detecting clinically relevant objects in medical images is a challenge despite large datasets due to the lack of detailed labels. To address the label issue, we utilize the scene-level labels with a detection architecture that incorporates natural language information. We present a challenging new set of radiologist paired bounding box and natural language annotations on the publicly available MIMIC-CXR dataset especially focussed on pneumonia and pneumothorax. Along with the dataset, we present a joint vision language weakly supervised transformer layer-selected one-stage dual head detection architecture (LITERATI) alongside strong baseline comparisons with class activation mapping (CAM), gradient CAM, and relevant implementations on the NIH ChestXray-14 and MIMIC-CXR dataset. Borrowing from advances in vision language architectures, the LITERATI method demonstrates joint image and referring expression (objects localized in the image using natural language) input for detection that scales in a purely weakly supervised fashion. The architectural modifications address three obstacles -- implementing a supervised vision and language detection method in a weakly supervised fashion, incorporating clinical referring expression natural language information, and generating high fidelity detections with map probabilities. Nevertheless, the challenging clinical nature of the radiologist annotations including subtle references, multi-instance specifications, and relatively verbose underlying medical reports, ensures the vision language detection task at scale remains stimulating for future investigation.