A Programmable Approach to Neural Network Compression
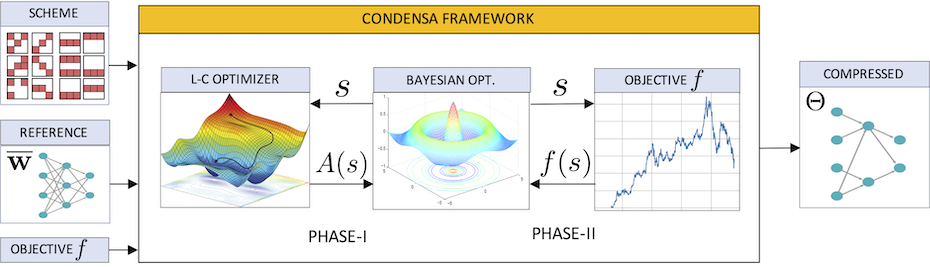
Deep neural networks (DNNs) frequently contain far more weights, represented at a higher precision, than are required for the specific task, which they are trained to perform. Consequently, they can often be compressed using techniques such as weight pruning and quantization that reduce both the model size and inference time without appreciable loss in accuracy. However, finding the best compression strategy and corresponding target sparsity for a given DNN, hardware platform, and optimization objective currently requires expensive, frequently manual, trial-and-error experimentation. In this article, we introduce a programmable system for model compression called Condensa. Users programmatically compose simple operators, in Python, to build more complex and practically interesting compression strategies. Given a strategy and user-provided objective (such as minimization of running time), Condensa uses a novel Bayesian optimization-based algorithm to automatically infer desirable sparsities. Our experiments on four real-world DNNs demonstrate memory footprint and hardware runtime throughput improvements of 188x and 2.59x, respectively, using at most ten samples per search. We have released a reference implementation of Condensa at: https://github.com/NVlabs/condensa
Publication Date
External Links
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.