Proto-CLIP: Vision-Language Prototypical Network for Few-Shot Learning
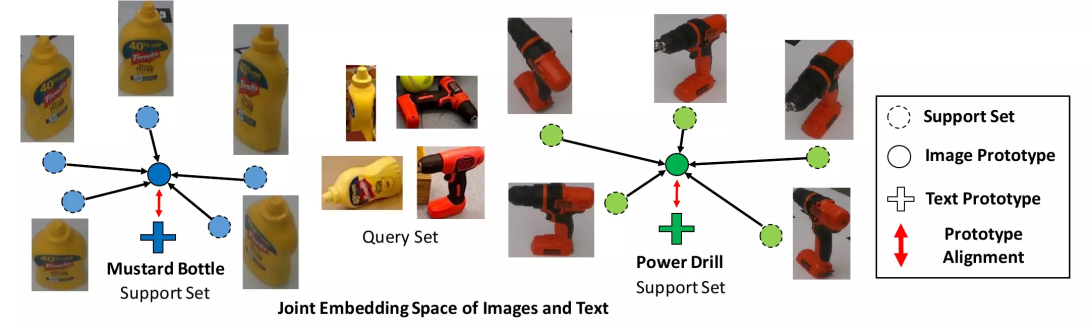
We propose a novel framework for few-shot learning by leveraging large-scale vision-language models such as CLIP. Motivated by unimodal prototypical networks for few-shot learning, we introduce Proto-CLIP which utilizes image prototypes and text prototypes for few-shot learning. Specifically, Proto-CLIP adapts the image and text encoder embeddings from CLIP in a joint fashion using few-shot examples. The embeddings from the two encoders are used to compute the respective prototypes of image classes for classification. During adaptation, we propose aligning the image and text prototypes of the corresponding classes. Such alignment is beneficial for few-shot classification due to the reinforced contributions from both types of prototypes. Proto-CLIP has both training-free and fine-tuned variants. We demonstrate the effectiveness of our method by conducting experiments on benchmark datasets for few-shot learning, as well as in the real world for robot perception. The project page can be found at https://irvlutd.github.io/Proto-CLIP.