SLIM: One-shot Quantization and Sparsity with Low-rank Approximation for LLM Weight Compression
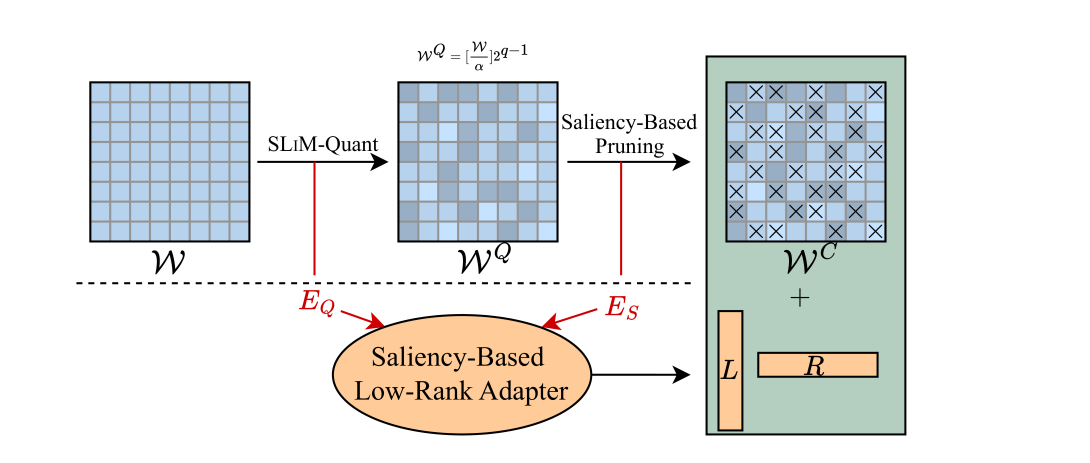
Conventional model compression techniques for LLMs address high memory consumption and slow inference challenges but typically require computationally expensive retraining to preserve accuracy. In contrast, one-shot compression methods eliminate retraining costs, but struggle to achieve accuracy comparable to dense models. This paper presents SLIM, a new one-shot compression framework that holistically integrates hardware-friendly quantization, sparsity, and low-rank approximation into a unified process. First, we formulate the quantization process using a probabilistic approach (SLIM-Quant) that enables us to apply uniform quantization. Then, we use an existing one-shot pruning method to apply semi-structured sparsity on top of the quantized weights. Finally, to compensate for the introduced aggregated quantization and sparsity error, we use a novel saliency function with unique invertible and additive features that enables us to mathematically compute the value of low-rank adapters. SLIM improves model accuracy by up to 5.66% (LLaMA-2-7B) for 2:4 sparsity with 4-bit weight quantization, outperforming prior methods. Models compressed with SLIM achieve up to 4.3× and 3.8× layer-wise speedup on Nvidia RTX3060 and A100 GPUs, respectively. Additionally, they achieve up to 0.23× end-to-end memory reduction in comparison to their dense counterparts. We also propose an optional PEFT recipe that further improves accuracy by up to 1.66% (LLaMA-2-13B) compared to SLIM without fine-tuning.