Software-Directed Techniques for Improved GPU Register File Utilization
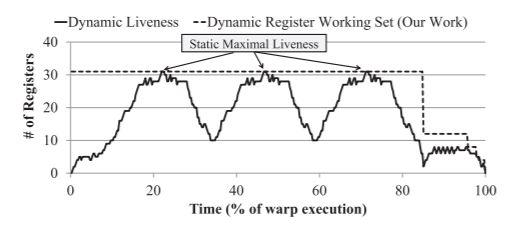
Throughput architectures such as GPUs require substantial hardware resources to hold the state of a massive number of simultaneously executing threads. While GPU register files are already enormous, reaching capacities of 256KB per streaming multiprocessor (SM), we find that nearly half of real-world applications we examined are register-bound and would benefit from a larger register file to enable more concurrent threads. This article seeks to increase the thread occupancy and improve performance of these register-bound applications by making more efficient use of the existing register file capacity. Our first technique eagerly deallocates register resources during execution. We show that releasing register resources based on value liveness as proposed in prior states of the art leads to unreliable performance and undue design complexity. To address these deficiencies, our article presents a novel compiler-driven approach that identifies and exploits last use of a register name (instead of the value contained within) to eagerly release register resources. Furthermore, while previous works have leveraged “scalar” and “narrow” operand properties of a program for various optimizations, their impact on thread occupancy has been relatively unexplored. Our article evaluates the effectiveness of these techniques in improving thread occupancy and demonstrates that while any one approach may fail to free very many registers, together they synergistically free enough registers to launch additional parallel work. An in-depth evaluation on a large suite of applications shows that just our early register technique outperforms previous work on dynamic register allocation, and together these approaches, on average, provide 12% performance speedup (23% higher thread occupancy) on register bound applications not already saturating other GPU resources.
Publication Date
Research Area
External Links
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.