Indirect Object-to-Robot Pose Estimation from an External Monocular RGB Camera
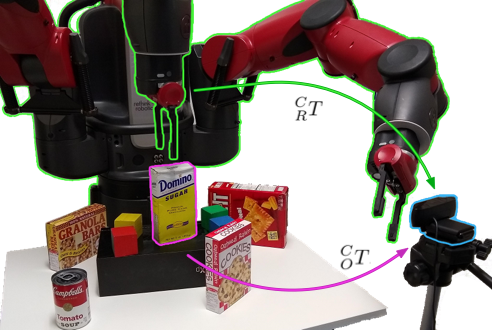
We present a robotic grasping system that uses a single external monocular RGB camera as input. The object-to-robot pose is computed indirectly by combining the output of two neural networks: one that estimates the object-to-camera pose, and another that estimates the robot-to-camera pose. Both networks are trained entirely on synthetic data, relying on domain randomization to bridge the sim-to-real gap. Because the latter network performs online camera calibration, the camera can be moved freely during execution without affecting the quality of the grasp. Experimental results analyze the effect of camera placement, image resolution, and pose refinement in the context of grasping several household objects. We also present results on a new set of 28 textured household toy grocery objects, which have been selected to be accessible to other researchers. To aid reproducibility of the research, we offer 3D scanned textured models, along with pre-trained weights for pose estimation.
Note: 3D models and network weights coming soon...