Self-Taught Recognizer: Toward Unsupervised Adaptation for Speech Foundation Models
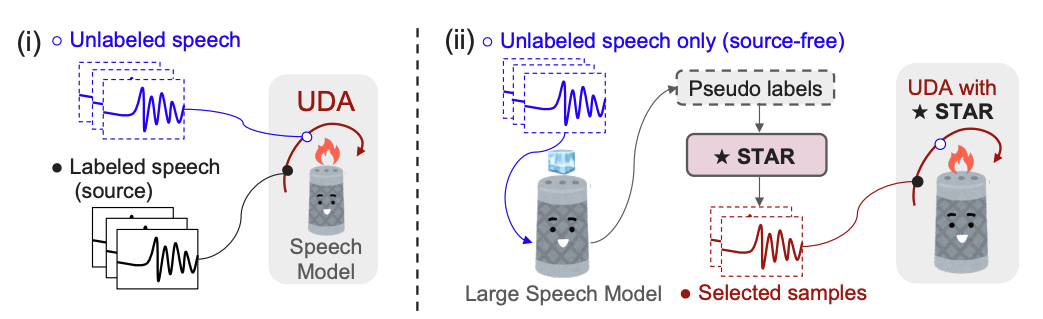
We propose an unsupervised adaptation framework, Self-TAught Recognizer (STAR), which leverages unlabeled data to enhance the robustness of automatic speech recognition (ASR) systems in diverse target domains, such as noise and accents. STAR is developed for prevalent speech foundation models based on Transformer-related architecture with auto-regressive decoding (e.g., Whisper, Canary). Specifically, we propose a novel indicator that empirically integrates step-wise information during decoding to assess the token-level quality of pseudo labels without ground truth, thereby guiding model updates for effective unsupervised adaptation. Experimental results show that STAR achieves an average of 13.5% relative reduction in word error rate across 14 target domains, and it sometimes even approaches the upper-bound performance of supervised adaptation. Surprisingly, we also observe that STAR prevents the adapted model from the common catastrophic forgetting problem without recalling source-domain data. Furthermore, STAR exhibits high data efficiency that only requires less than one-hour unlabeled data, and seamless generality to alternative large speech models and speech translation tasks