Audio Large Language Models Can Be Descriptive Speech Quality Evaluators
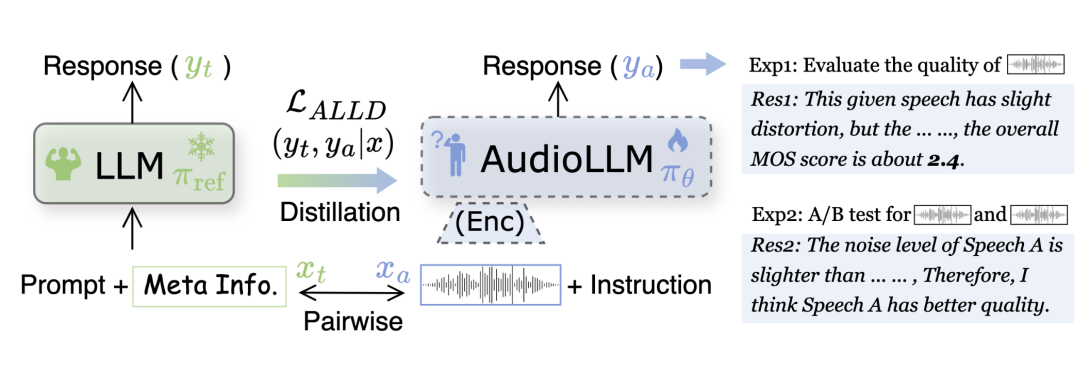
An ideal multimodal agent should be aware of the quality of its input modalities.
Recent advances have enabled large language models (LLMs) to incorporate auditory systems for handling various speech-related tasks. However, most audio
LLMs remain unaware of the quality of the speech they process. This limitation arises because speech quality evaluation is typically excluded from multi-task
training due to the lack of suitable datasets. To address this, we introduce the first
natural language-based speech evaluation corpus, generated from authentic human ratings. In addition to the overall Mean Opinion Score (MOS), this corpus
offers detailed analysis across multiple dimensions and identifies causes of quality
degradation. It also enables descriptive comparisons between two speech samples
(A/B tests) with human-like judgment. Leveraging this corpus, we propose an
alignment approach with LLM distillation (ALLD) to guide the audio LLM in
extracting relevant information from raw speech and generating meaningful responses. Experimental results demonstrate that ALLD outperforms the previous
state-of-the-art regression model in MOS prediction, with a mean square error of
0.17 and an A/B test accuracy of 98.6%. Additionally, the generated responses
achieve BLEU scores of 25.8 and 30.2 on two tasks, surpassing the capabilities of
task-specific models. This work advances the comprehensive perception of speech
signals by audio LLMs, contributing to the development of real-world auditory
and sensory intelligent agents.