MemcachedGPU: Scaling-up Scale-out Key-value Stores
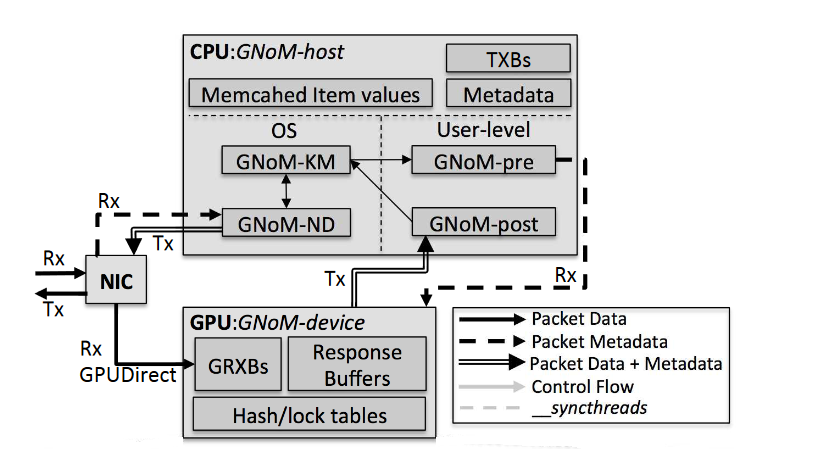
This paper tackles the challenges of obtaining more efficient data center computing while maintaining low latency, low cost, programmability, and the potential for workload consolidation. We introduce GNoM, a software framework enabling energy-efficient, latency bandwidth optimized UDP network and application processing on GPUs. GNoM handles the data movement and task management to facilitate the development of high-throughput UDP network services on GPUs. We use GNoM to develop MemcachedGPU, an accelerated key-value store, and evaluate the full system on contemporary hardware. MemcachedGPU achieves ~10 GbE line-rate processing of ~13 million requests per second (MRPS) while delivering an efficiency of 62 thousand RPS per Watt (KRPS/W) on a high-performance GPU and 84.8 KRPS/W on a low-power GPU. This closely matches the throughput of an optimized FPGA implementation while providing up to 79% of the energy-efficiency on the low-power GPU. Additionally, the low-power GPU can potentially improve cost-efficiency (KRPS/$) up to 17% over a state-of-the-art CPU implementation. At 8 MRPS, MemcachedGPU achieves a 95-percentile RTT latency under 300μs on both GPUs. An offline limit study on the low-power GPU suggests that MemcachedGPU may continue scaling throughput and energy-efficiency up to 28.5 MRPS and 127 KRPS/W respectively.
Publication Date
Published in
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.