Single-pass Parallel Prefix Scan with Decoupled Look-back
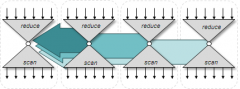
We describe a work-efficient, communication-avoiding, single-pass method for the parallel computation of prefix scan. When consuming input from memory, our algorithm requires only ~2n data movement: n inputs are read, n outputs are written. Our method embodies a decoupled look-back strategy that performs redundant work to dissociate local computation from the latencies of global prefix propagation. Implemented by the CUB library of parallel primitives for GPU architectures, the performance throughput of our parallel prefix scan approaches that of copy operations. Furthermore, the single-pass nature of our method allows it to be adapted for (1) in-place compaction behavior, and (2) in-situ global allocation within computations that oversubscribe the processor.