IamNN: Iterative and Adaptive Mobile Neural Network for Efficient Image Classification
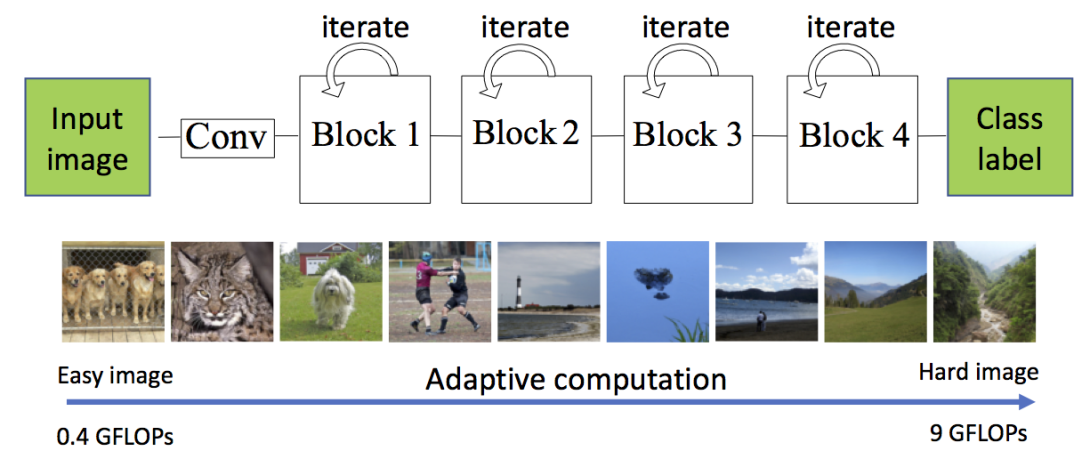
Deep residual networks (ResNets) made a recent breakthrough in deep learning. The core idea of ResNets is to have shortcut connections between layers that allow the network to be much deeper while still being easy to optimize avoiding vanishing gradients. These shortcut connections have interesting side-effects that make ResNets behave differently from other typical network architectures. In this work we use these properties to design a network based on a ResNet but with parameter sharing and with adaptive computation time. The resulting network is much smaller than the original network and can adapt the computational cost to the complexity of the input image.
Publication Date
Research Area
Uploaded Files
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.