On the Importance of Stereo for Accurate Depth Estimation: An Efficient Semi-Supervised Deep Neural Network Approach
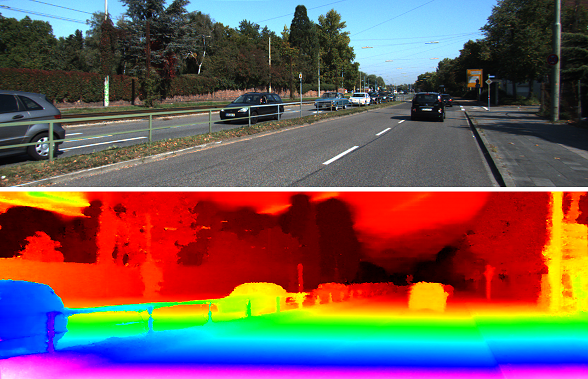
We revisit the problem of visual depth estimation in the context of autonomous vehicles. Despite the progress on monocular depth estimation in recent years, we show that the gap between monocular and stereo depth accuracy remains large--a particularly relevant result due to the prevalent reliance upon monocular cameras by vehicles that are expected to be self-driving. We argue that the challenges of removing this gap are significant, owing to fundamental limitations of monocular vision. As a result, we focus our efforts on depth estimation by stereo. We propose a novel semi-supervised learning approach to training a deep stereo neural network, along with a novel architecture containing a machine-learned argmax layer and a custom runtime that enables a smaller version of our stereo DNN to run on an embedded GPU. Competitive results are shown on the KITTI 2015 stereo dataset. We also evaluate the recent progress of stereo algorithms by measuring the impact upon accuracy of various design criteria.
Publication Date
Published in
Research Area
External Links
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.