Reblur2Deblur: Deblurring Videos via Self-Supervised Learning
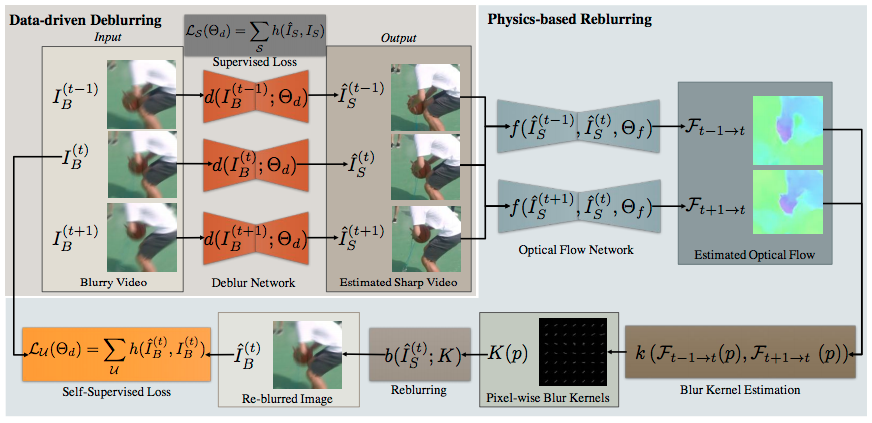
Motion blur is a fundamental problem in computer vision as it impacts image quality and hinders inference. Traditional deblurring algorithms leverage the physics of the image formation model and use hand-crafted priors: they usually produce results that better reflect the underlying scene, but present artifacts. Recent learning-based methods implicitly extract the distribution of natural images directly from the data and use it to synthesize plausible images. Their results are impressive, but they are not always faithful to the content of the latent image. We present an approach that bridges the two. Our method fine-tunes existing deblurring neural networks in a self-supervised fashion by enforcing that the output, when blurred based on the optical flow between subsequent frames, matches the input blurry image. We show that our method significantly improves the performance of existing methods on several datasets both visually and in terms of image quality metrics.
Publication Date
External Links
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.