Neural Inverse Rendering of an Indoor Scene from a Single Image
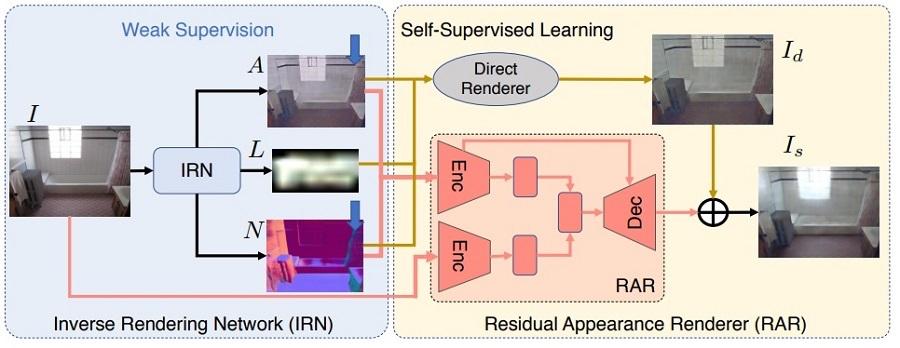
Inverse rendering aims to estimate physical attributes of a scene, e.g., reflectance, geometry, and lighting, from image(s). Inverse rendering has been studied primarily for single objects or with methods that solve for only one of the scene attributes. We propose the first learning based approach that jointly estimates albedo, normals, and lighting of an indoor scene from a single image. Our key contribution is the Residual Appearance Renderer (RAR), which can be trained to synthesize complex appearance effects (e.g., inter-reflection, cast shadows, near-field illumination, and realistic shading), which would be neglected otherwise. This enables us to perform self-supervised learning on real data using a reconstruction loss, based on re-synthesizing the input image from the estimated components. We finetune with real data after pretraining with synthetic data. To this end we use physically-based rendering to synthesize a large-scale training dataset. Experimental results show that our approach outperforms state-of-the-art methods that estimate one or more scene attributes.
Publication Date
Research Area
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.