Angular Visual Hardness
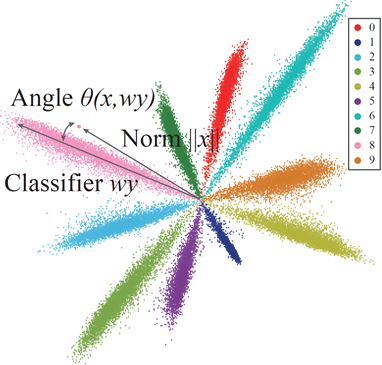
Recent convolutional neural networks (CNNs) have led to impressive performance but often suffer from poor calibration. They tend to be overconfident, with the model confidence not always reflecting the underlying true ambiguity and hardness. In this paper, we propose angular visual hardness (AVH), a score given by the normalized angular distance between the sample feature embedding and the target classifier to measure sample hardness. We validate this score with an in-depth and extensive scientific study, and observe that CNN models with the highest accuracy also have the best AVH scores. This agrees with an earlier finding that state-of-art models improve on the classification of harder examples. We observe that the training dynamics of AVH is vastly different compared to the training loss. Specifically, AVH quickly reaches a plateau for all samples even though the training loss keeps improving. This suggests the need for designing better loss functions that can target harder examples more effectively. We also find that AVH has a statistically significant correlation with human visual hardness. Finally, we demonstrate the benefit of AVH to a variety of applications such as self-training for domain adaptation and domain generalization.