Joint Disentangling and Adaptation for Cross-Domain Person Re-Identification
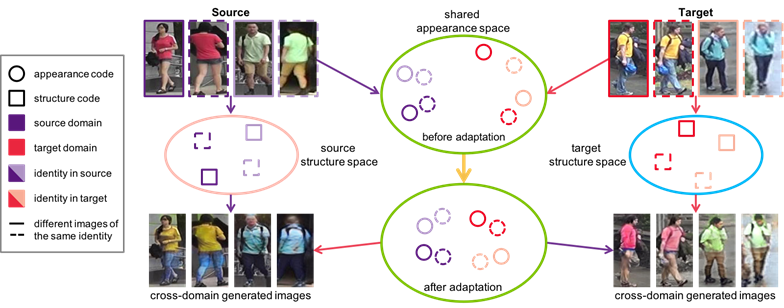
Although a significant progress has been witnessed in supervised person re-identification (re-id), it remains challenging to generalize re-id models to new domains due to the huge domain gaps. Recently, there has been a growing interest in using unsupervised domain adaptation to address this scalability issue. Existing methods typically conduct adaptation on the representation space that contains both id-related and id-unrelated factors, thus inevitably undermining the adaptation efficacy of id-related features. In this paper, we seek to improve adaptation by purifying the representation space to be adapted. To this end, we propose a joint learning framework that disentangles id-related/unrelated features and enforces adaptation to work on the id-related feature space exclusively. Our model involves a disentangling module that encodes cross-domain images into a shared appearance space and two separate structure spaces, and an adaptation module that performs adversarial alignment and self-training on the shared appearance space. The two modules are co-designed to be mutually beneficial. Extensive experiments demonstrate that the proposed joint learning framework outperforms the state-of-the-art methods by clear margins.