Flexion: A Quantitative Metric for Flexibility in DNN Accelerators
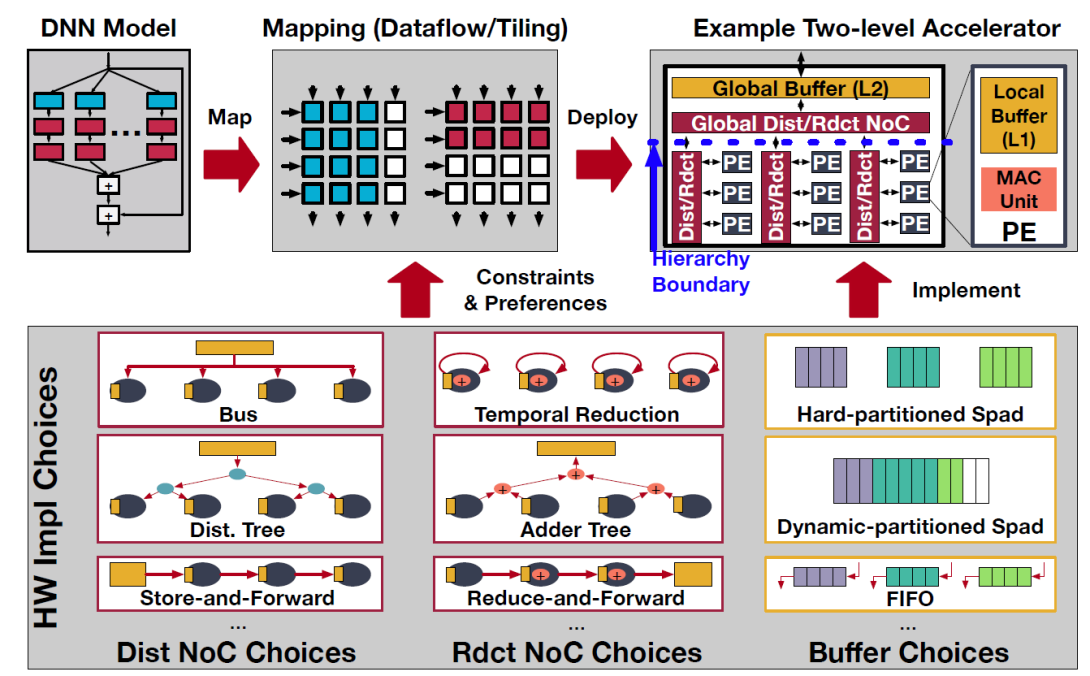
Dataflow and tile size choices, which we collectively refer to as mappings, dictate the efficiency (i.e., latency and energy) of DNN accelerators. Rapidly evolving DNN models is one of the major challenges for DNN accelerators since the optimal mapping heavily depends on the layer shape and size. To maintain high efficiency across multiple DNN models, flexible accelerators that can support multiple mappings have emerged. However, we currently lack a metric to evaluate accelerator flexibility and quantitatively compare their capability to run different mappings. In this work, we formally define the concept of flexibility in DNN accelerators and propose flexion (flexibility fraction), flexion, which is a quantitative metric of mapping flexibility on DNN accelerators. We codify the formalism we construct and evaluate the flexibility of accelerators based on Eyeriss, NVDLA, and TPUv1. We show that Eyeriss-like accelerator is 2.2x and 17.0x more flexible (i.e., capable of running more mappings) than NVDLA and TPUv1-based accelerators on selected ResNet-50 and MobileNetV2 layers. This work is the first work to enable such a quantitative comparison of the flexibility of accelerators.
Publication Date
Published in
External Links
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.