A Formalism of DNN Accelerator Flexibility
The high efficiency of domain-specific hardware accelerators for machine learning (ML) has come from
specialization, with the trade-off of less configurability/ flexibility. There is growing interest in developing
flexible ML accelerators to make them future-proof to the rapid evolution of Deep Neural Networks (DNNs).
However, the notion of accelerator flexibility has always been used in an informal manner, restricting computer
architects from conducting systematic apples-to-apples design-space exploration (DSE) across trillions of
choices. In this work, we formally define accelerator flexibility and show how it can be integrated for DSE.
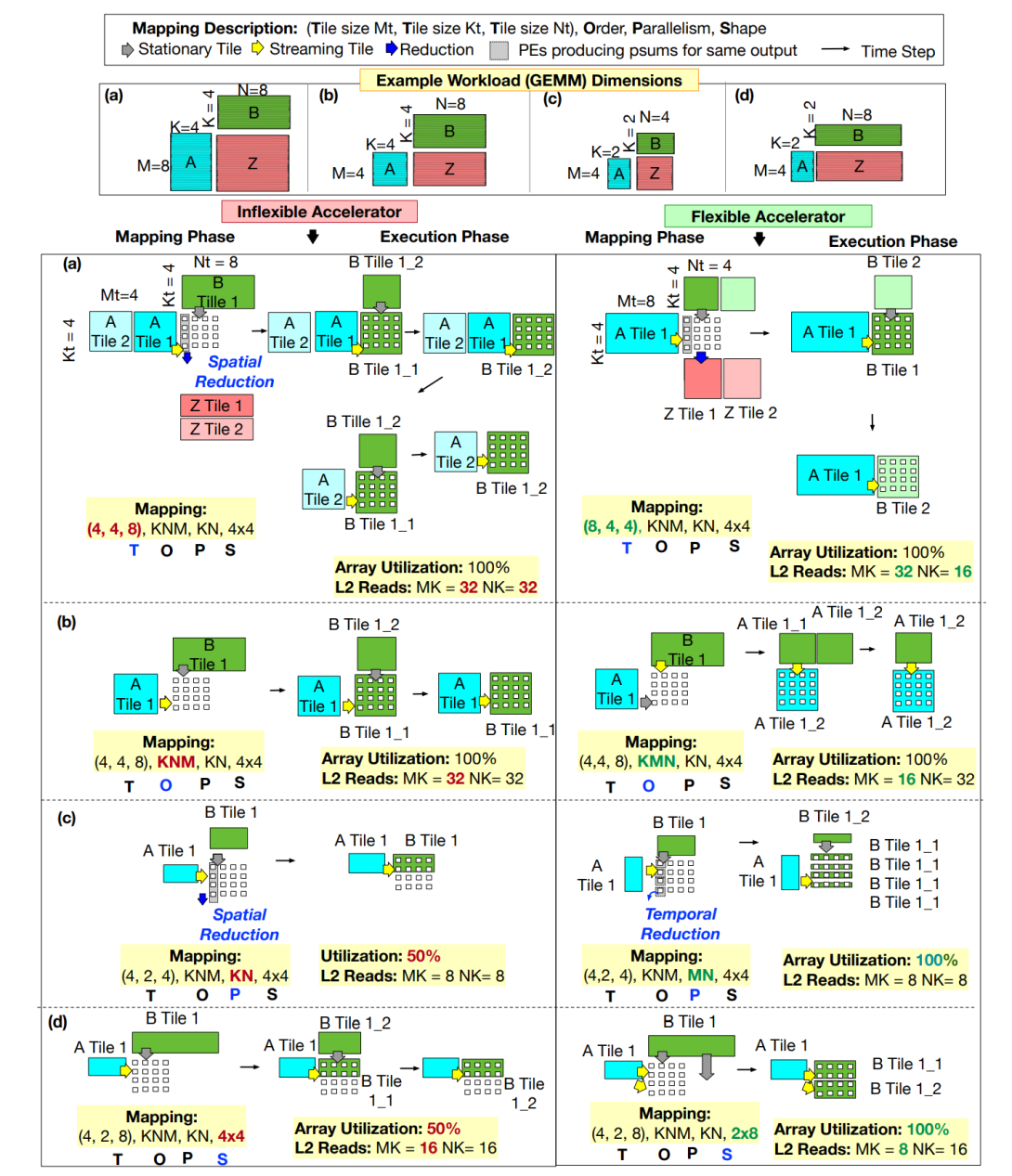
Specifically, we capture DNN accelerator flexibility across four axes: tiling, ordering, parallelization, and
array shape. We categorize existing accelerators into 16 classes based on their axes of flexibility support,
and define a precise quantification of the degree of flexibility of an accelerator across each axis. We leverage
these to develop a novel flexibility-aware DSE framework. We demonstrate how this can be used to perform
first-of-their-kind evaluations, including an isolation study to identify the individual impact of the flexibility
axes. We demonstrate that adding flexibility features to a hypothetical DNN accelerator designed in 2014
improves runtime on future (i.e., present-day) DNNs by 11.8× geomean.
Publication Date
Published in
Research Area
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.