Self Adaptive Reconfigurable Arrays (SARA): Learning Flexible GEMM Accelerator Configuration and Mapping-space using ML
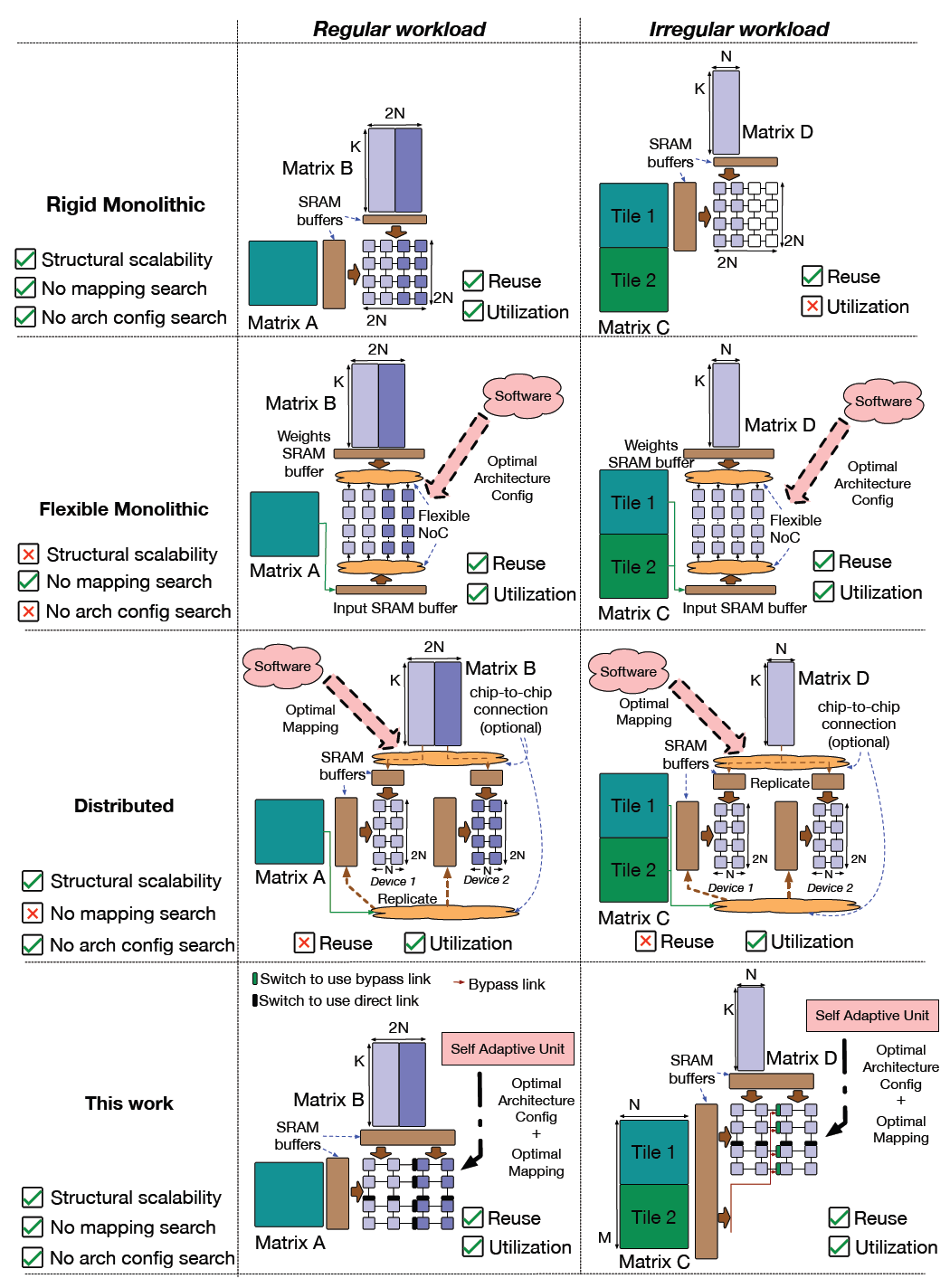
This work demonstrates a scalable reconfigurable accelerator (RA) architecture designed to extract maximum performance and energy efficiency for GEMM workloads. We also present a self-adaptive (SA) unit, which runs a learnt model for one-shot configuration optimization in hardware offloading the software stack thus easing the deployment of the proposed design. We evaluate an instance of the proposed methodology with a 32.768 TOPS reference implementation called SAGAR, that can provide the same mapping flexibility as a compute equivalent distributed system while achieving 3.5× more power efficiency and 3.2x higher compute density demonstrated via architectural and post-layout simulation.
Publication Date
Published in
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.