Robust and Controllable Object-Centric Learning through Energy-based Models
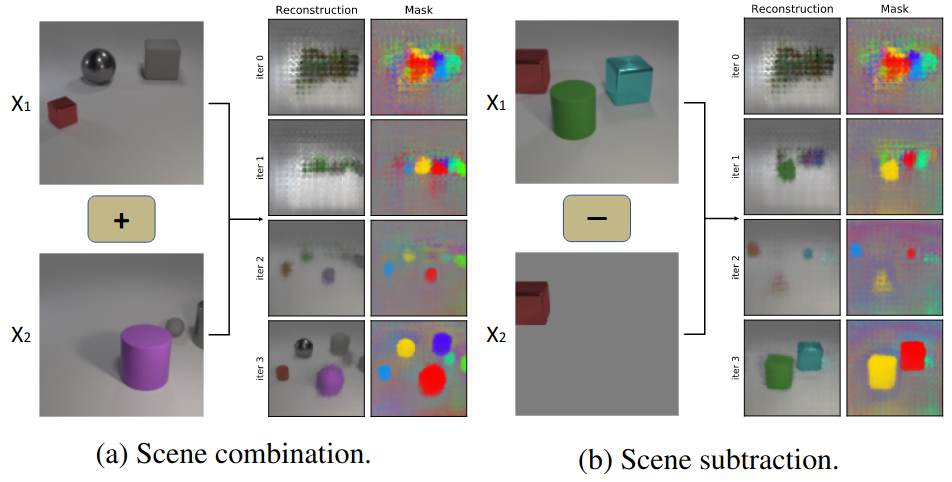
Humans are remarkably good at understanding and reasoning about complex visual scenes. The capability to decompose low-level observations into discrete objects allows us to build a grounded abstract representation and identify the compositional structure of the world. Accordingly, it is a crucial step for machine learning models to be capable of inferring objects and their properties from visual scenes without explicit supervision. However, existing works on object-centric representation learning either rely on tailor-made neural network modules or strong probabilistic assumptions in the underlying generative and inference processes. In this work, we present EGO, a conceptually simple and general approach to learning object-centric representations through an energy-based model. By forming a permutation-invariant energy function using vanilla attention blocks readily available in Transformers, we can infer object-centric latent variables via gradient-based MCMC methods where permutation equivariance is automatically guaranteed. We show that EGO can be easily integrated into existing architectures and can effectively extract high-quality object-centric representations, leading to better segmentation accuracy and competitive downstream task performance. Further, empirical evaluations show that EGO’s learned representations are robust against distribution shift. Finally, we demonstrate the effectiveness of EGO in systematic compositional generalization, by re-composing learned energy functions for novel scene generation and manipulation.