Tree-structured Policy Planning with Learned Behavior Models
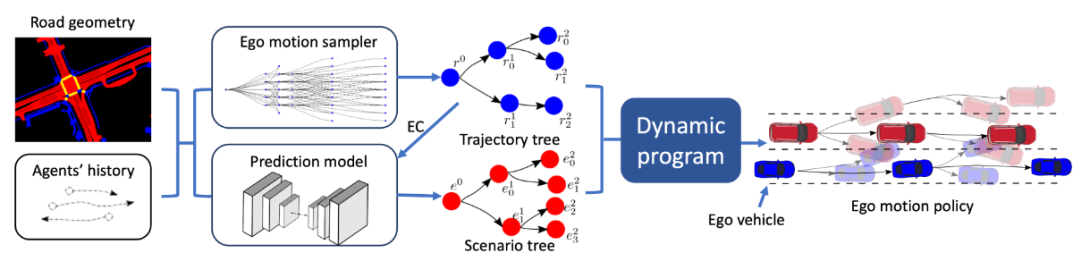
Autonomous vehicles (AVs) need to reason about the multimodal behavior of neighboring agents while planning their own motion. Many existing trajectory planners seek a single trajectory that performs well under all plausible futures simultaneously, ignoring bi-directional interactions and thus leading to overly conservative plans. Policy planning, whereby the ego agent plans a policy that reacts to the environment’s multimodal behavior, is a promising direction as it can account for the action-reaction interactions between the AV and the environment. However, most existing policy planners do not scale to the complexity of real autonomous vehicle applications: they are either not compatible with modern deep learning prediction models, not interpretable, or not able to generate high quality trajectories. To fill this gap, we propose Tree Policy Planning (TPP), a policy planner that is compatible with state-of-the-art deep learning prediction models, generates multistage motion plans, and accounts for the influence of ego agent on the environment behavior. The key idea of TPP is to reduce the continuous optimization problem into a tractable discrete MDP through the construction of two tree structures: an ego trajectory tree for ego trajectory options, and a scenario tree for multi-modal ego-conditioned environment predictions. We demonstrate the efficacy of TPP in closed-loop simulations based on real-world nuScenes dataset and results show that TPP scales to realistic AV scenarios and significantly outperforms non-policy baselines.
Publication Date
External Links
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.