Haisor: Human-aware Indoor Scene Optimization via Deep Reinforcement Learning
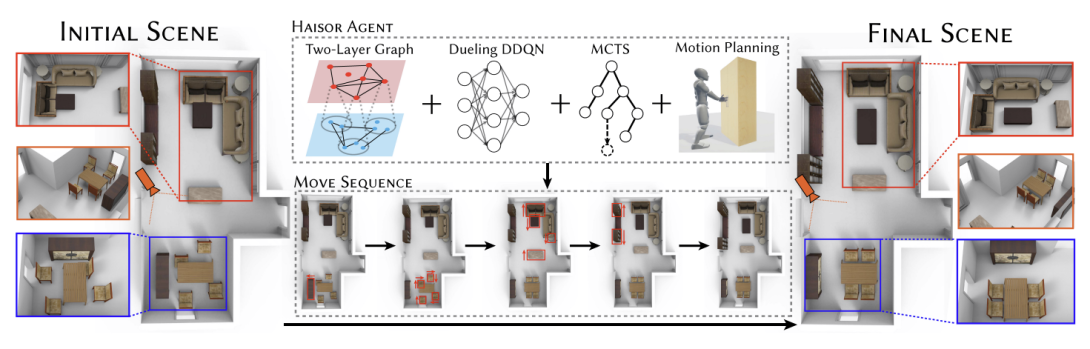
3D scene synthesis facilitates and benefits many real-world applications. Most scene generators focus on making indoor scenes plausible via learning from training data and leveraging extra constraints such as adjacency and symmetry. Although the generated 3D scenes are mostly plausible with visually realistic layouts, they can be functionally unsuitable for human users to navigate and interact with furniture. Our key observation is that human activity plays a critical role and sufficient free space is essential for human-scene interactions. This is exactly where many existing synthesized scenes fail—the seemingly correct layouts are often not fit for living. To tackle this, we present a human-aware optimization framework Haisor for 3D indoor scene arrangement via reinforcement learning, which aims to find an action sequence to optimize the indoor scene layout automatically. Based on the hierarchical scene graph representation, an optimal action sequence is predicted and performed via Deep Q-Learning with Monte Carlo Tree Search (MCTS), where MCTS is our key feature to search for the optimal solution in long-term sequences and large action space. Multiple human-aware rewards are designed as our core criteria of human-scene interaction, aiming to identify the next smart action by leveraging powerful reinforcement learning. Our framework is optimized end-to-end by giving the indoor scenes with part-level furniture layout including part mobility information. Furthermore, our methodology is extensible and allows utilizing different reward designs to achieve personalized indoor scene synthesis. Extensive experiments demonstrate that our approach optimizes the layout of 3D indoor scenes in a human-aware manner, which is more realistic and plausible than original state-of-the-art generator results, and our approach produces superior smart actions, outperforming alternative baselines