ACGD: Visual Multitask Policy Learning with Asymmetric Critic Guided Distillation
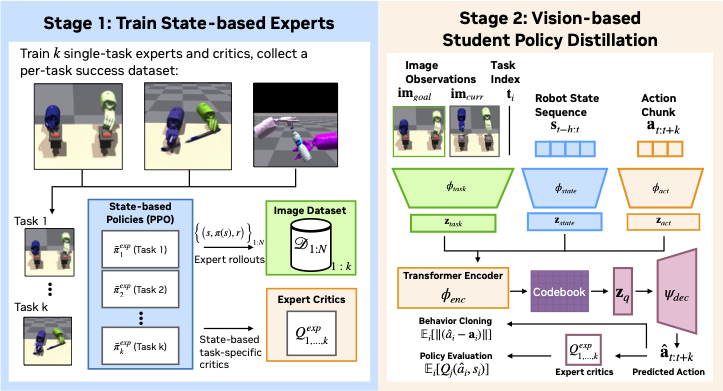
ACGD introduces a novel approach to visual multitask policy learning by leveraging asymmetric critics to guide the distillation process. Our method trains single-task expert policies and their corresponding critics using privileged state information. These experts are then used to distill a unified multi-task student policy that can generalize across diverse tasks. The student policy employs a VQ-VAE architecture with a transformer-based encoder and decoder, enabling it to predict discrete action tokens from image observations and robot states. We evaluate ACGD on three challenging multi-task domains—MyoDex, BiDex, and OpDex—and demonstrate significant improvements over baseline methods such as BC-RNN+DAgger, ACT, and MT-PPO. ACGD achieves a 10-15% performance boost across various dexterous manipulation benchmarks, showcasing its effectiveness in scaling to high degrees of freedom and complex visuomotor tasks.