CudaDMA: Optimizing GPU Memory Bandwidth via Warp Specialization
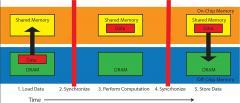
As the computational power of GPUs continues to scale with Moore's Law, an increasing number of applications are becoming limited by memory bandwidth. We propose an approach for programming GPUs with tightly-coupled specialized DMA warps for performing memory transfers between on-chip and off-chip memories. Separate DMA warps improve memory bandwidth utilization by better exploiting available memory-level parallelism and by leveraging efficient inter-warp producer-consumer synchronization mechanisms. DMA warps also improve programmer productivity by decoupling the need for thread array shapes to match data layout. To illustrate the benefits of this approach, we present an extensible API, CudaDMA, that encapsulates synchronization and common sequential and strided data transfer patterns. Using CudaDMA, we demonstrate speedup of up to 1.37x on representative synthetic micro-benchmarks, and 1.15x-3.2x on several kernels from scientific applications written in CUDA running on NVIDIA Fermi GPUs.
Publication Date
Published in
Research Area
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.