Priority-Based Cache Allocation in Throughput Processors
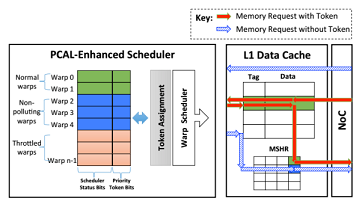
GPUs employ massive multithreading and fast context switching to provide high throughput and hide memory latency. Multithreading can Increase contention for various system resources, however, that may result In suboptimal utilization of shared resources. Previous research has proposed variants of throttling thread-level parallelism to reduce cache contention and improve performance. Throttling approaches can, however, lead to under-utilizing thread contexts, on-chip interconnect, and off-chip memory bandwidth. This paper proposes to tightly couple the thread scheduling mechanism with the cache management algorithms such that GPU cache pollution is minimized while off-chip memory throughput is enhanced. We propose priority-based cache allocation (PCAL) that provides preferential cache capacity to a subset of high-priority threads while simultaneously allowing lower priority threads to execute without contending for the cache. By tuning thread-level parallelism while both optimizing caching efficiency as well as other shared resource usage, PCAL builds upon previous thread throttling approaches, improving overall performance by an average 17% with maximum 51%.
Publication Date
Research Area
External Links
Uploaded Files
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.