Unlocking Bandwidth for GPUs in CC-NUMA systems
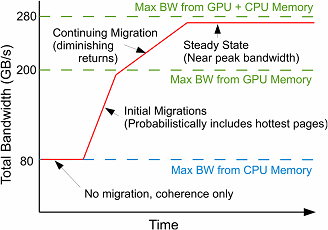
Historically, GPU-based HPC applications have had a substantial memory bandwidth advantage over CPU-based workloads due to using GDDR rather than DDR memory. However, past GPUs required a restricted programming model where application data was allocated up front and explicitly copied into GPU memory before launching a GPU kernel by the programmer. Recently, GPUs have eased this requirement and now can employ on-demand software page migration between CPU and GPU memory to obviate explicit copying. In the near future, CC-NUMA GPU-CPU systems will appear where software page migration is an optional choice and hardware cache-coherence can also support the GPU accessing CPU memory directly. In this work, we describe the trade-offs and considerations in relying on hardware cache-coherence mechanisms versus using software page migration to optimize the performance of memory-intensive GPU workloads. We show that page migration decisions based on page access frequency alone are a poor solution and that a broader solution using virtual address-based program locality to enable aggressive memory prefetching combined with bandwidth balancing is required to maximize performance. We present a software runtime system requiring minimal hardware support that, on average, outperforms CC-NUMA-based accesses by 1.95 ×, performs 6% better than the legacy CPU to GPU memcpy regime by intelligently using both CPU and GPU memory bandwidth, and comes within 28% of oracular page placement, all while maintaining the relaxed memory semantics of modern GPUs.
Publication Date
Research Area
External Links
Uploaded Files
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.