Architecting an Energy-Efficient DRAM System for GPUs
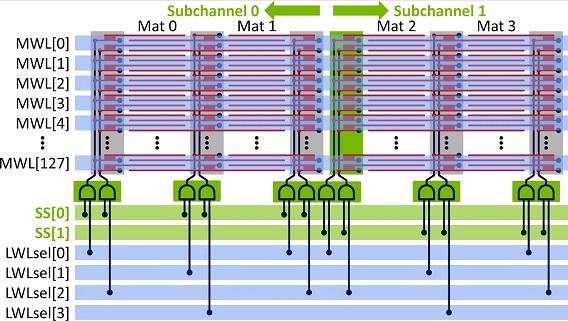
This paper proposes an energy-efficient, high-throughput DRAM architecture for GPUs and throughput processors. In these systems, requests from thousands of concurrent threads compete for a limited number of DRAM row buffers. As a result, only a fraction of the data fetched into a row buffer is used, leading to significant energy overheads. Our proposed DRAM architecture exploits the hierarchical organization of a DRAM bank to reduce the minimum row activation granularity. To avoid significant incremental area with this approach, we must partition the DRAM datapath into a number of semi-independent subchannels. These narrow subchannels increase data toggling energy which we mitigate using a static data reordering scheme designed to lower the toggle rate. This design has 35% lower energy consumption than a die-stacked DRAM with 2.6% area overhead. The resulting architecture, when augmented with an improved memory access protocol, can support parallel operations across the semi-independent subchannels, thereby improving system performance by 13% on average for a range of workloads.
Publication Date
Research Area
External Links
Uploaded Files
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.