Sim-to-Real Transfer of Accurate Grasping with Eye-In-Hand Observations and Continuous Control
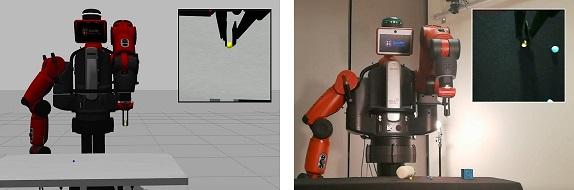
In the context of deep learning for robotics, we show effective method of training a real robot to grasp a tiny sphere (1:37cm of diameter), with an original combination of system design choices. We decompose the end-to-end system into a vision module and a closed-loop controller module. The two modules use target object segmentation as their common interface. The vision module extracts information from the robot end-effector camera, in the form of a binary segmentation mask of the target. We train it to achieve effective domain transfer by composing real background images with simulated images of the target. The controller module takes as input the binary segmentation mask, and thus is agnostic to visual discrepancies between simulated and real environments. We train our closed-loop controller in simulation using imitation learning and show it is robust with respect to discrepancies between the dynamic model of the simulated and real robot: when combined with eye-in-hand observations, we achieve a 90% success rate in grasping a tiny sphere with a real robot. The controller can generalize to unseen scenarios where the target is moving and even learns to recover from failures.