On the Trend of Resilience for GPU-Dense Systems
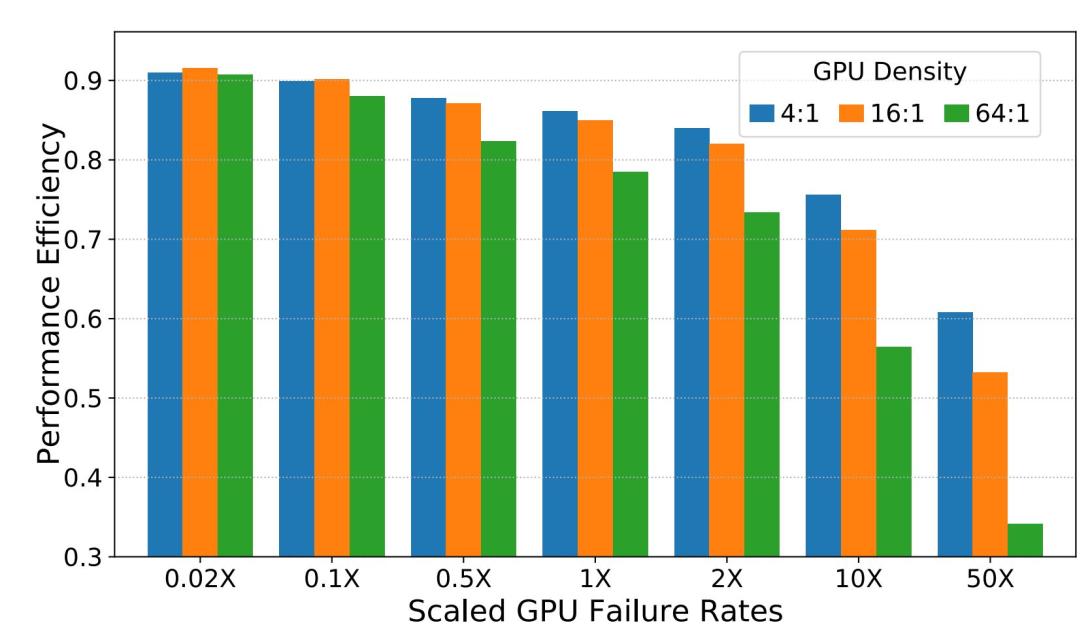
Emerging high-performance computing (HPC) systems show a tendency towards heterogeneous nodes that are dense with accelerators such as GPUs. They offer higher computational power at lower energy and cost than homogeneous CPU-only nodes. While an accelerator-rich machine reduces the total number of compute nodes required to achieve a performance target, a single node becomes susceptible to accelerator failures as well as sharing intra-node resources with many accelerators. Such failures must be recovered by end-to-end resilience schemes such as checkpoint-restart. However, preserving a large amount of local state within accelerators for checkpointing incurs significant overhead. This trend reveals a new challenge for the resilience in accelerator-dense systems. We study its impact in multi-level checkpointing systems and with burst buffers. We quantify the system-level efficiency for resilience, sweeping the failure rate, system scale, and GPU density. Our multi-level checkpoint-restart model shows that the efficiency begins to drop at a 16:1 GPU-to-CPU ratio in a 3.6 EFLOP system and a ratio of 64:1 degrades overall system efficiency by 5%. Furthermore, we quantify the system-level impact of possible design considerations for the resilience in GPU-dense systems to mitigate this challenge.
Publication Date
External Links
Uploaded Files
Award
Copyright
This material is posted here with permission of the IEEE. Internal or personal use of this material is permitted. However, permission to reprint/republish this material for advertising or promotional purposes or for creating new collective works for resale or redistribution must be obtained from the IEEE by writing to pubs-permissions@ieee.org.