GPU Snapshot: Checkpoint Offloading for GPU-Dense Systems
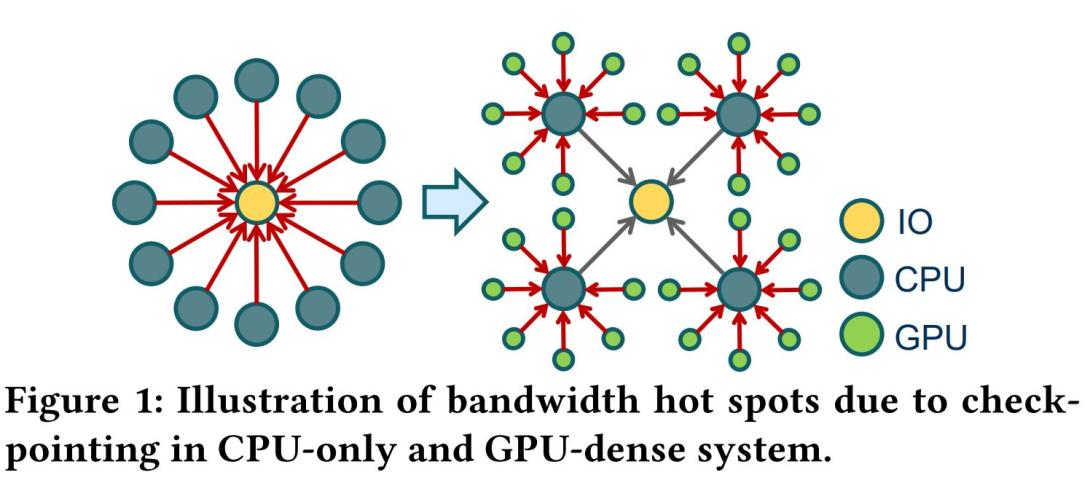
Future High-Performance Computing (HPC) systems will likely be composed of accelerator-dense heterogeneous computers because accelerators are able to deliver higher performance at lower costs, socket counts and energy consumption. Such acceleratordense nodes pose a reliability challenge because preserving a large amount of state within accelerators for checkpointing incurs significant overhead. Checkpointing multiple accelerators at the same time, which is necessary to obtain a consistent coordinated checkpoint, overwhelms the host interconnect, memory and IO bandwidths. We propose GPU Snapshot to mitigate this issue by: (1) enabling a fast logical snapshot to be taken, while actual checkpointed state is transferred asynchronously to alleviate bandwidth hot spots; (2) using incremental checkpoints that reduce the volume of data transferred; and (3) checkpoint offloading to limit accelerator complexity and effectively utilize the host. As a concrete example, we describe and evaluate the design tradeoffs of GPU Snapshot in the context of a GPU-dense multi-exascale HPC system. We demonstrate 4–40X checkpoint overhead reductions at the node level, which enables a system with GPU Snapshot to approach the performance of a system with idealized GPU checkpointing.
Publication Date
Published in
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.