Near-Memory Data Transformation for Efficient Sparse Matrix Multi-Vector Multiplication
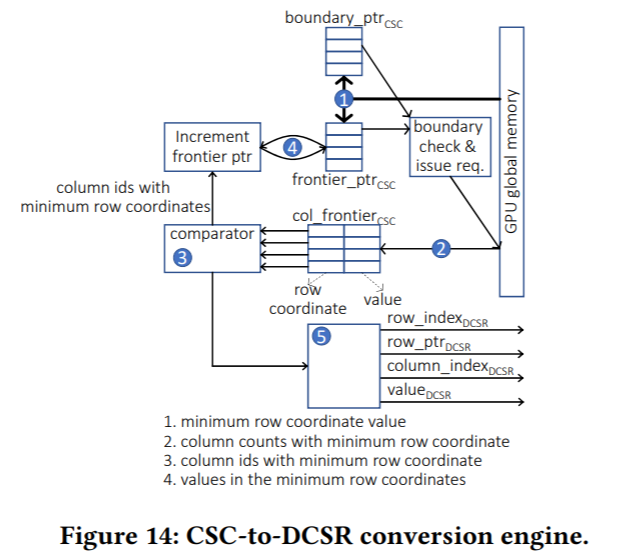
Efficient manipulation of sparse matrices is critical to a wide range of HPC applications. Increasingly, GPUs are used to accelerate these sparse matrix operations. We study one common operation, Sparse Matrix Multi-Vector Multiplication (SpMM), and evaluate the impact of the sparsity, distribution of non-zero elements, and tiletraversal strategies on GPU implementations. Using these insights, we determine that operating on these sparse matrices in a Densified Compressed Sparse Row (DCSR) is well-suited to the parallel warp-synchronous execution model of the GPU processing elements. Preprocessing or storing the sparse matrix in the DCSR format, however, often requires significantly more memory storage and access bandwidth than conventional Compressed Sparse Row (CSR) or Compressed Sparse Column (CSC) formats. Therefore, we propose a near-memory transform engine to dynamically create DCSR formatted tiles for the GPU processing elements from the CSC formatted matrix in memory. This work enhances a GPU’s last-level cache/memory controller unit to act as an efficient translator between the compute-optimized representation of data and its corresponding storage/bandwidth-optimized format to accelerate sparse workloads. Our approach achieves 2.26× better performance on average compared to the vendor supplied optimized library for sparse matrix operations, cuSPARSE.
Publication Date
Research Area
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.