Speculative Reconvergence for Improved SIMT Efficiency
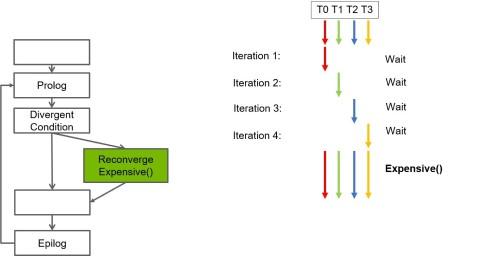
GPUs perform most efficiently when all threads in a warp execute the same sequence of instructions convergently. However, when threads in a warp encounter a divergent branch, the hardware serializes the execution of diverged paths. We consider a class of convergence opportunities wherein multiple threads are expected to eventually execute a given segment of code, but not all threads arrive at the same time, resulting in serialized duplicate execution of common code subsequences such as function calls and loop bodies. Our goal is to promote convergence by helping threads that execute common code arrive together before allowing execution to proceed. We propose a new user-guided compiler mechanism, Speculative Reconvergence, to help identify and exploit previously untapped convergence opportunities that increase SIMT efficiency and improve performance. For the set of workloads we study, we see improvements ranging from 10% to 3× in both SIMT efficiency and in performance.
Publication Date
External Links
Uploaded Files
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.