GPU Domain Specialization via Composable On-Package Architecture
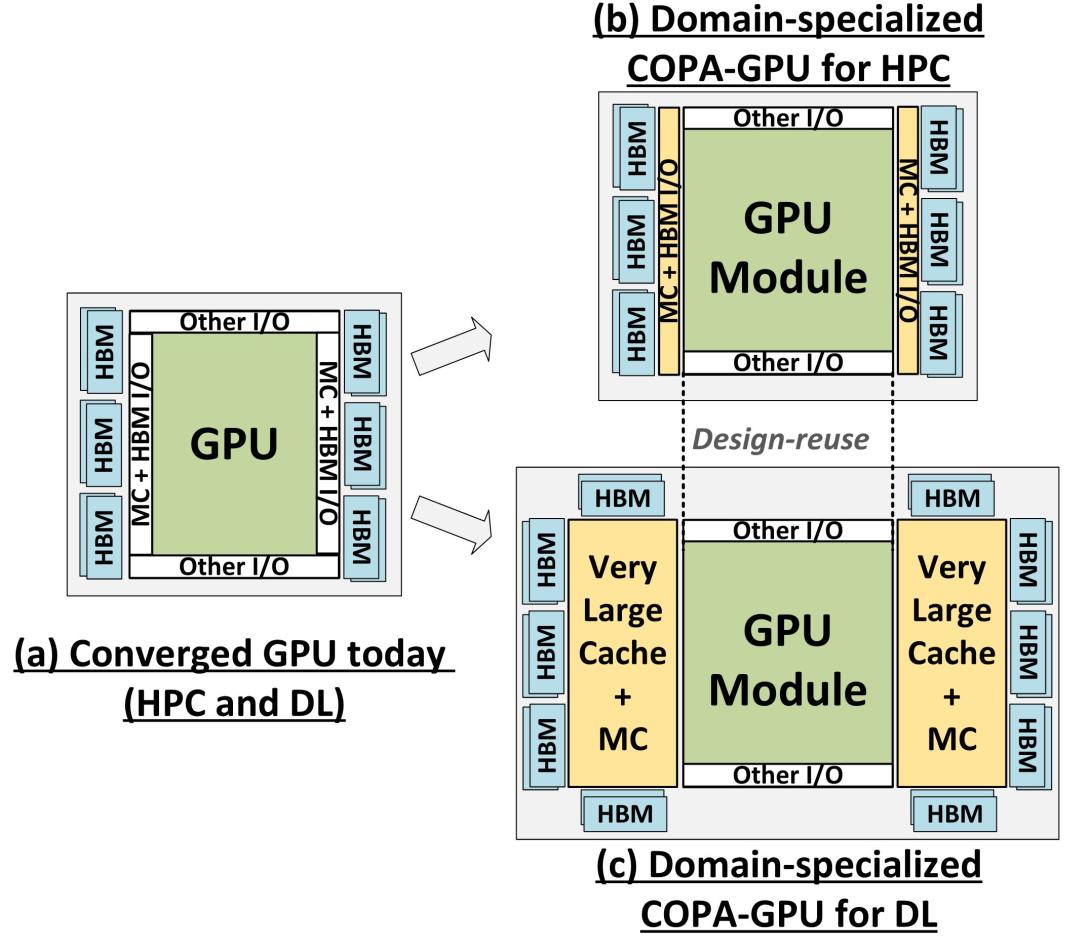
As GPUs scale their low-precision matrix math throughput to boost deep learning (DL) performance, they upset the balance between math throughput and memory system capabilities. We demonstrate that a converged GPU design trying to address diverging architectural requirements between FP32 (or larger)-based HPC and FP16 (or smaller)-based DL workloads results in sub-optimal configurations for either of the application domains. We argue that a Composable On-PAckage GPU (COPA-GPU) architecture to provide domain-specialized GPU products is the most practical solution to these diverging requirements. A COPA-GPU leverages multi-chip-module disaggregation to support maximal design reuse, along with memory system specialization per application domain. We show how a COPA-GPU enables DL-specialized products by modular augmentation of the baseline GPU architecture with up to 4× higher off-die bandwidth, 32× larger on-package cache, and 2.3× higher DRAM bandwidth and capacity, while conveniently supporting scaled-down HPC-oriented designs. This work explores the microarchitectural design necessary to enable composable GPUs and evaluates the benefits composability can provide to HPC, DL training, and DL inference. We show that when compared to a converged GPU design, a DL-optimized COPA-GPU featuring a combination of 16× larger cache capacity and 1.6× higher DRAM bandwidth scales per-GPU training and inference performance by 31% and 35%, respectively, and reduces the number of GPU instances by 50% in scale-out training scenarios.
Publication Date
Research Area
External Links
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.