HEAT: Hardware-Efficient Automatic Tensor Decomposition for Transformer Compression
Transformers have attained superior performance in natural language processing and computer vision. Their self-attention and feedforward layers are overparameterized, limiting inference speed and energy efficiency. Tensor decomposition is a promising technique to reduce parameter redundancy by leveraging tensor algebraic properties to express the parameters in a factorized form. Prior efforts used manual or heuristic factorization settings without hardware-aware customization, resulting in poor hardware efficiencies and large performance degradation.
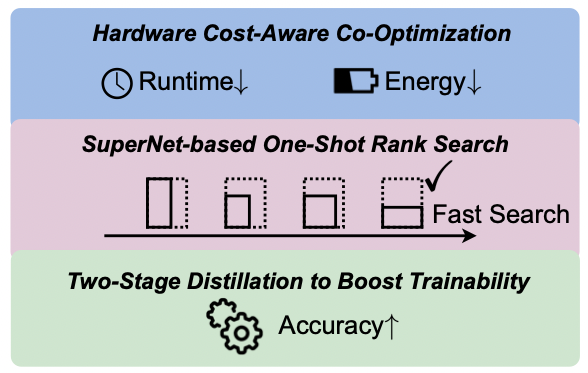
In this work, we propose a hardware-aware tensor decomposition framework, dubbed HEAT, that enables efficient exploration of the exponential space of possible decompositions and automates the choice of tensorization shape and decomposition rank with hardware-aware co-optimization. We jointly investigate tensor contraction path optimizations and a fused Einsum mapping strategy to bridge the gap between theoretical benefits and real hardware efficiency improvement. Our two-stage knowledge distillation flow resolves the trainability bottleneck and thus significantly boosts the final accuracy of factorized Transformers. Overall, we experimentally show that our hardware-aware factorized BERT variants reduce the energy-delay product by 5.7x with less than 1.1% accuracy loss and achieve a better efficiency-accuracy Pareto frontier than hand-tuned and heuristic baselines.