Global Context Vision Transformers
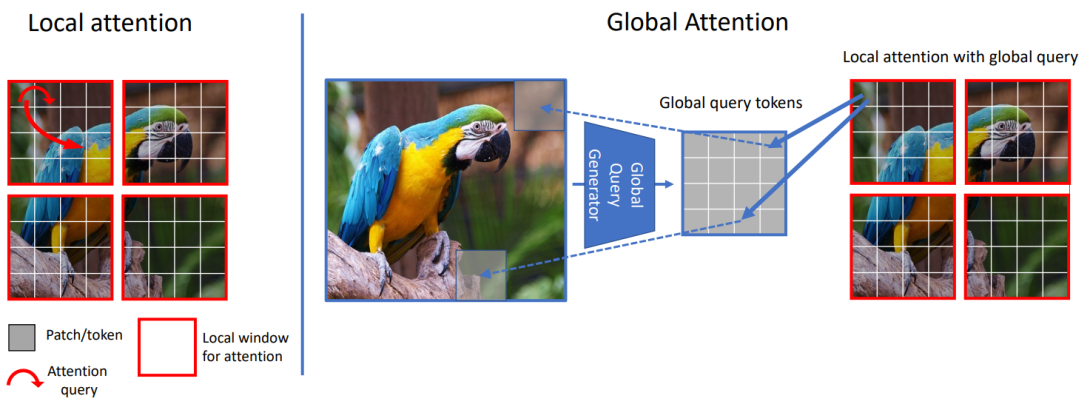
We propose global context vision transformer (GC ViT), a novel architecture that enhances parameter and compute utilization for computer vision. Our method leverages global context self-attention modules, joint with standard local self-attention, to effectively and efficiently model both long and short-range spatial interactions, without the need for expensive operations such as computing attention masks or shifting local windows. In addition, we address the lack of the inductive bias in ViTs, and propose to leverage a modified fused inverted residual blocks in our architecture. Our proposed GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, the variants of GC ViT with 51 M, 90 M and 201 M parameters achieve 84.3%, 85.0% and 85.7% Top-1 accuracy, respectively, at 224 x 224 image resolution and without any pre-training, hence surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based MaxViT and Swin Transformer by a large margin. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation, and semantic segmentation using MS COCO and ADE20K datasets outperform prior work consistently. Specifically, GC ViT with a 4-scale DINO detection head achieves a box AP of 58.3% on MS COCO dataset.