Seeing What Matters: Generalizable AI-generated Video Detection with Forensic-Oriented Augmentation
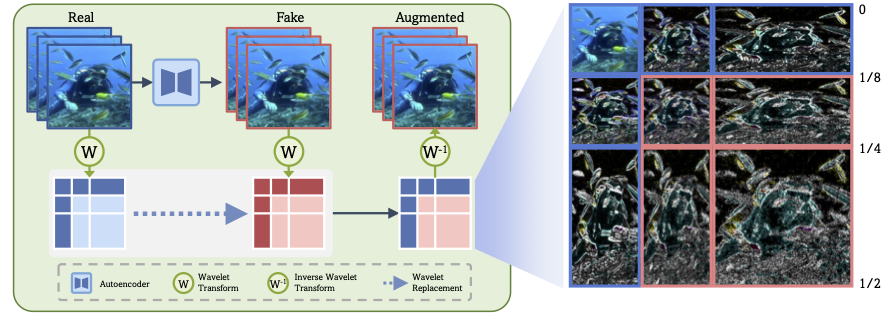
Synthetic video generation is progressing very rapidly. The latest models can produce very realistic high-resolution videos that are virtually indistinguishable from real ones. Although several video forensic detectors have been recently proposed, they often exhibit poor generalization, which limits their applicability in a real-world scenario. Our key insight to overcome this issue is to guide the detector towards seeing what really matters. In fact, a well-designed forensic classifier should focus on identifying intrinsic low-level artifacts introduced by a generative architecture rather than relying on high-level semantic flaws that characterize a specific model. In this work, first, we study different generative architectures, searching and identifying discriminative features that are unbiased, robust to impairments, and shared across models. Then, we introduce a novel forensic-oriented data augmentation strategy based on the wavelet decomposition and replace specific frequency-related bands to drive the model to exploit more relevant forensic cues. Our novel training paradigm improves the generalizability of AI-generated video detectors, without the need for complex algorithms and large datasets that include multiple synthetic generators. To evaluate our approach, we train the detector using data from a single generative model and test it against videos produced by a wide range of other models. Despite its simplicity, our method achieves a significant accuracy improvement over state-of-the-art detectors and obtains excellent results even on very recent generative models, such as NOVA and FLUX.