Opportunities for RTL and Gate Level Simulation using GPUs
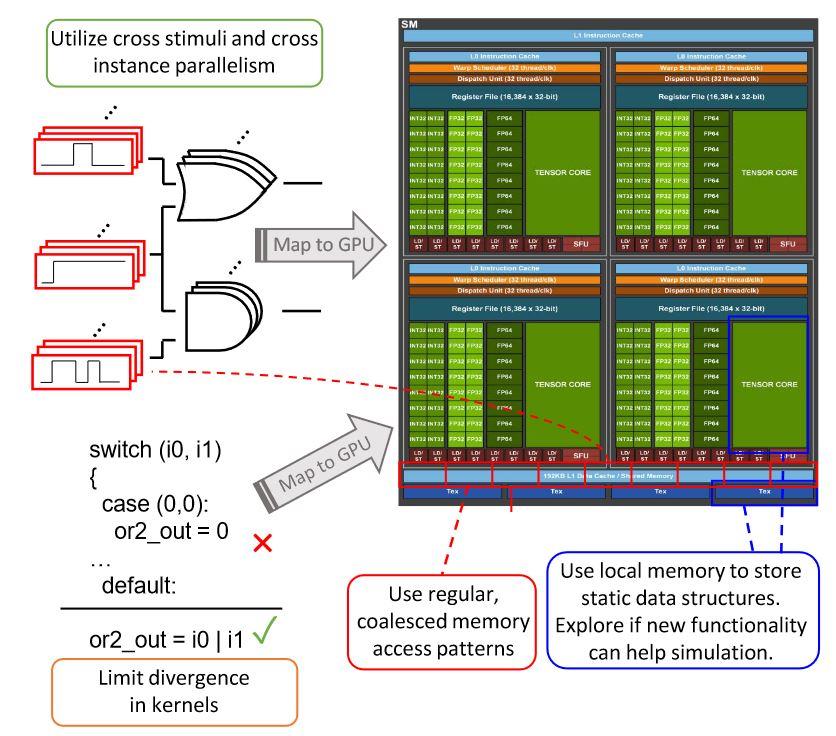
This paper summarizes the opportunities in accelerating simulation on parallel processing hardware platforms such as GPUs. First, we give a summary of prior art. Then, we propose the idea that coding frameworks usually used for popular machine learning (ML) topics, such as PyTorch/DGL.ai, can also be used for exploring simulation purposes. We demo a crude oblivious two-value cycle gate-level simulator using the higher level ML framework APIs that exhibits >20X speedup, despite its simplistic construction. Next, we summarize recent advances in GPU features that may provide additional opportunities to further state-of-the-art results. Finally, we conclude and touch upon some potential areas for furthering research into the topic of GPU accelerated simulation.
(Invited talk for ICCAD tutorial - GPU Acceleration in CAD: Opportunities and Challenges)
Publication Date
Research Area
External Links
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.