Softermax: Hardware/Software Co-Design of an Efficient Softmax for Transformers
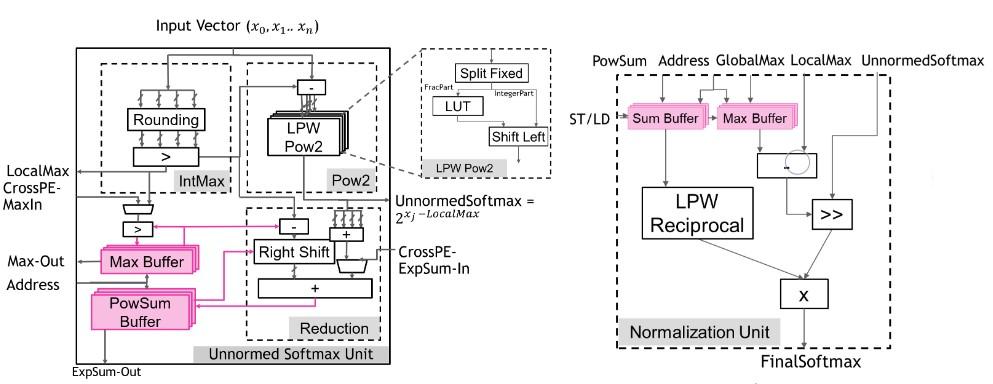
Transformers have transformed the field of natural language processing. This performance is largely attributed to the use of stacked self-attention layers, each of which consists of matrix multiplies as well as softmax operations. As a result, unlike other neural networks, the softmax operation accounts for a significant fraction of the total run-time of Transformers. To address this, we propose Softermax, a hardware-friendly softmax design. Softermax consists of base replacement, low-precision softmax computations, and an online normalization calculation. We show Softermax results in 2.35x the energy efficiency at 0.90x the size of a comparable baseline, with negligible impact on network accuracy.
Publication Date
Published in
Copyright
Copyright by the Association for Computing Machinery, Inc. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, to republish, to post on servers, or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from Publications Dept, ACM Inc., fax +1 (212) 869-0481, or permissions@acm.org. The definitive version of this paper can be found at ACM's Digital Library http://www.acm.org/dl/.