LNS-Madam: Low-Precision Training in Logarithmic Number System Using Multiplicative Weight Update
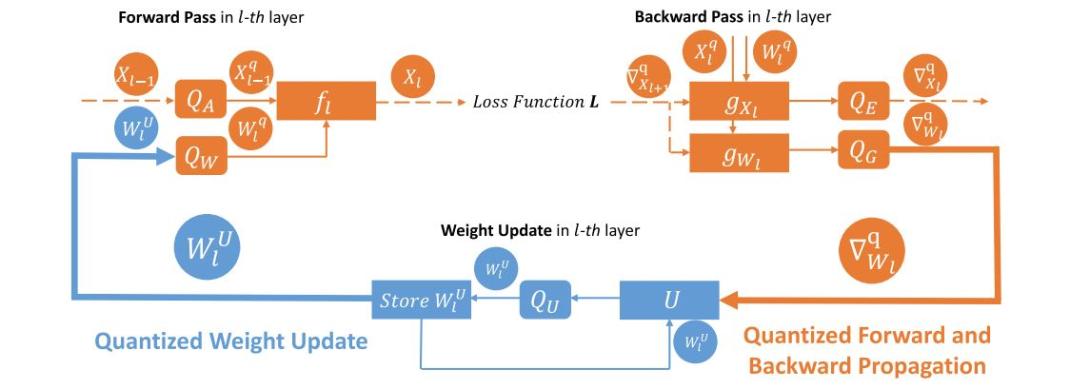
Representing deep neural networks (DNNs) in low-precision is a promising approach to enable efficient acceleration and memory reduction. Previous methods that train DNNs in low-precision typically keep a copy of weights in high-precision during the weight updates. Directly training with low-precision weights leads to accuracy degradation due to complex interactions between the low-precision number systems and the learning algorithms. To address this issue, we develop a co-designed low-precision training framework, termed LNS-Madam, in which we jointly design a logarithmic number system (LNS) and a multiplicative weight update algorithm (Madam). We prove that LNS-Madam results in low quantization error during weight updates, leading to stable performance even if the precision is limited. We further propose a hardware design of LNS-Madam that resolves practical challenges in implementing an efficient datapath for LNS computations. Our implementation effectively reduces energy overhead incurred by LNS-to-integer conversion and partial sum accumulation. Experimental results show that LNS-Madam achieves comparable accuracy to full-precision counterparts with only 8 bits on popular computer vision and natural language tasks. Compared to FP32 and FP8, LNS-Madam reduces the energy consumption by over 90% and 55%, respectively.
Publication Date
External Links
Copyright
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 License. For more information, see https://creativecommons.org/licenses/by-nc-nd/4.0/