Avatar Fingerprinting for Authorized Use of Synthetic Talking-Head Videos
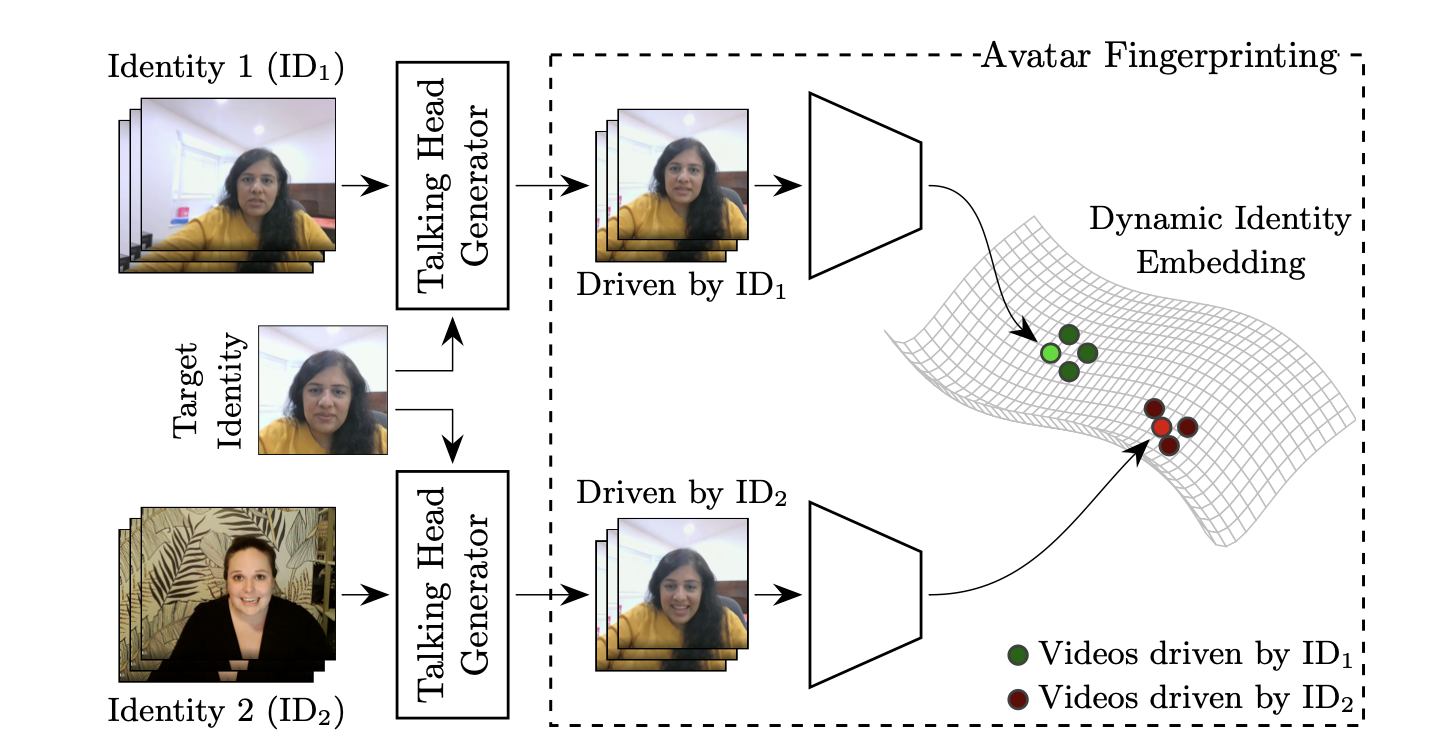
Modern deep learning-based video portrait generators render synthetic talking-head videos with impressive levels of photorealism, ushering in new user experiences such as videoconferencing with limited-bandwidth connectivity. Their safe adoption, however, requires a mechanism to verify if the rendered video is trustworthy. For instance, in videoconferencing we must identify cases when a synthetic video portrait uses the appearance of an individual without their consent. We term this task ''avatar fingerprinting''. We propose to tackle it by leveraging the observation that each person emotes in unique ways and has characteristic facial motion signatures. These signatures can be directly linked to the person ''driving'' a synthetic talking-head video. We learn an embedding in which the motion signatures derived from videos driven by one individual are clustered together, and pushed away from those of others, regardless of the facial appearance in the synthetic video. This embedding can serve as a tool to help verify authorized use of a synthetic talking-head video. Avatar fingerprinting algorithms will be critical as talking head generators become more ubiquitous, and yet no large scale datasets exist for this new task. Therefore, we contribute a large dataset of people delivering scripted and improvised short monologues, accompanied by synthetic videos in which we render videos of one person using the facial appearance of another. Since our dataset contains human subjects' facial data, we have taken many steps to ensure proper use and governance, including: IRB approval, informed consent prior to data capture, removing subject identity information, pre-specifying the subject matter that can be discussed in the videos, allowing subjects the freedom to revoke our access to their provided data at any point in future (and stipulating that interested third parties maintain current contact information with us so we can convey these changes to them). Lastly, we acknowledge the societal importance of introducing guardrails for the use of talking-head generation technology, and note that we present this work as a step towards trustworthy use of such technologies.